
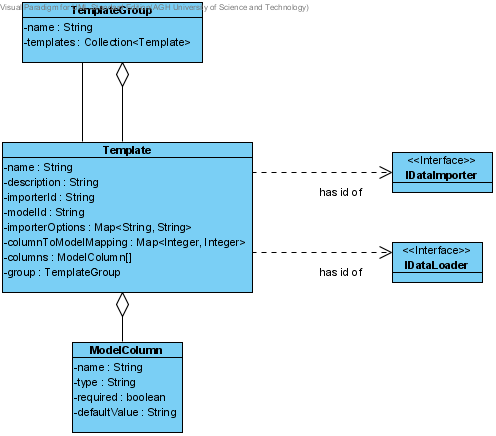
Szablon opisuje sposób importu danych z jednego typu pliku do jednego modelu dziedzinowego. Rysunek 1. przedstawia diagram klas opisujący szablon.
Rysunek 1.
Każdy szablon identyfikowany jest po nazwie, dodatkowo posiada opis, który zawiera informację o zastosowaniu szablonu. Szablon definiuje typ importera danych (IDataImporter) oraz klasę wczytującą dane (IDataLoader) za pomocą ich identyfikatorów (importerId i modelId).
Do interpretacji danych służy mapa mapująca numery kolumn w pliku wejściowym na typy danych (np. numer telefonu głównego, numer konta bankowego). Kody typów danych są zależne od klasy wczytującej dane, która jest odpowiedzialna za interpretacje danych wejściowych. W obecnej implementacji klasy implementujące IDataLoader korzystają z pomocniczej klasy''mapper'', która przechowuje informacje o znaczeniu kodów.
Szabolny mogą posiadać również opcje importera (mapa importerOptions). Opcje te definiowane są przez konkretną implementację importera danych i tylko przez niego ''rozumiane''. Importer może pobrać opcję po jej nazwie. Przykładowo importer CsvDataImporter posiada jedna opcję Separator określającą znak separujący kolumny.
Dodatkowo szablon przechowuje informacje o kolumnach (tablice columns), które wykorzystywane są podczas importu. Każda kolumna identyfikowana jest po nazwie, posiada swój typ (string, int, date, etc) oraz flagę określającą czy kolumna jest niezbędna do pomyślnego importu. Opcjonalnie kolumna może posiadać domyślną wartość. Jeśli podczas importu komórka w kolumnie jest pusta to jej wartość zostanie zastąpiona wartością domyślną.
Szablony przechowywane są w postaci plików XML, których format zdefiniowany jest przez schemat: templateSchema.xsd
Szablony pogrupowane są w grupy (TemplateGroup). Grupy te agregują szablony o podobnym zastosowaniu (np. szablony dotyczące billingów) i służą jedynie uporządkowaniu wielu szablonów.