Rozszerzanie importera
Dodawanie nowego tokenizatora
Tokenizetor jest zależny od formatu pliku wejściowego - na jego podstawie definiuje sposób konwersji strumienia danych wejściowych (z pliku) do listy tabel rekordów.
Istnieje możliwość dodania, w prosty sposób, nowego rozszerzenia pliku do istniejącego już tokenizetora. Aby to zrobić wystarczy w rozszerzeniu (extension) danego tokenizatora dodać nowe rozszerzenie fileextension, ustawiając jego unikalny identyfikator oraz wartość rozszerzenia pliku (np. csv, txt, xls).
Aby dodać do importera nowy tokenizator należy:
- Utworzyć nowy tokenizator, spełniający następujące warunki:
- klasa tokenizatora musi implementować interfejs IImportTokenizer lub rozszerzać abstrakcyjną klasę AbstractImportTokenizer
- tokenizetor musi posiadać 0-argumentowy konstruktor
- metoda tokenize musi dzielić strumień danych na tokeny, korzystając z podanych opcji tokenizatora, kodowania, oraz ograniczając się do podanej ilości wierszy
- Dodać nowy tokenizator jako extension do punktu rozszerzeń pl.edu.agh.cast.importer.base.tokenizer
- wartość atrybutu point musi wskazywać na klasę nowego tokenizatora
- Dodać rozszerzenia plików obsługiwanych przez nowy tokenizetor jako extension do punktu rozszerzeń fileextension danego tokenizatora
- wartość rozszerzenia pliku musi wskazywać na konkretne rozszerzenie: np. csv, txt, xls
Dodawanie nowego analizatora (typu danych)
Analizator rozumiany jest w kontekście konkretnego typu danych. Typy danych pozwalają na weryfikację importowanych danych na poziomie ich poprawności syntaktycznej (np. poprawnego formatu daty, poprawnych wartości dla kierunku połączeń przychodzących/wychodzących).
Tabela 1 przedstawia listę aktualnie zaimplementowanych typów danych.
| Typ danych |
Klasa typu danych |
Analizator |
Wartość domyślna parametru analizatora |
Opis |
|---|
| Czas |
TimeDataType |
TimeAnalyzer |
HH:mm:ss |
Typ czasu |
| Data |
DateDataType |
DateAnalyzer |
dd-MM-yyyy |
Typ daty |
| Data i czas |
DateAndTimeDataType |
DateAndTimeAnalyzer |
dd-MM-yyyy HH:mm:ss |
Typ daty i czasu |
| Kierunek |
DirectionDataType |
DirectionAnalyzer |
brak |
Kierunek połączenia |
| Liczba |
Integer |
IntegerAnalyzer |
brak |
Typ liczbowy |
| Tekst |
String |
StringAnalyzer |
brak |
Typ tekstowy |
Rysunek 1: Relacja klas typów danych wykorzystywanych w procesie importu danych.
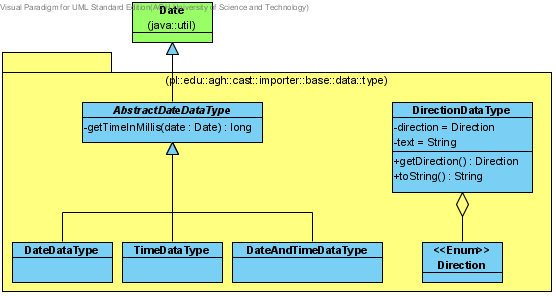
Jeden analizator można użyć do analizy wielu typów danych. W kreatorze importu, kolumnom danych przypisuje się konkretne typy danych, które następnie są analizowane przy pomocy przypisanego do nich analizatora.
Aby dodać do importera nowy typ danych oraz nowy analizator należy:
- Utworzyć nowy typ danych
- Utworzyć nowy analizator, spełniający następujące warunki:
- klasa analizatora musi implementować interfejs IAnalyzer
- analizator musi posiadać 0-argumentowy konstruktor oraz settery dla wszystkich jego niezbędnych parametrów
- metoda analyze analizatora musi z tokenu w postaci Stringa utworzyć listę obiektów nowego typu danych
- metoda getReturnTypes analizatora musi wskazywać na obiekty nowego typu danych
- Dodać nowy typ danych jako extension do punktu rozszerzeń pl.edu.agh.cast.importer.base.datatype
- wartość atrybutu analyzer musi wskazywać na klasę nowego analizatora
Dodawanie nowej reguły konwersji
Każda reguła konwersji dotyczy konkretnego pola (pól) dziedzinowego (-ych). Załóżmy, że chcemy dodać regułę konwersji dla pola, dla którego zdefiniowany został już odpowiedni interfejs.
Aby dodać do importera nową regułę konwersji należy:
- Utworzyć regułę konwersji, spełniającą następujące warunki:
- klasa reguły musi implementować wszystkie interfejsy reguł dla pól dziedzinowych, których wartości produkuje, np. (w modelu podstawowym) jeżeli reguła "wyciąga" z wiersza tylko wartość węzła głównego to będzie implementowała tylko interfejs ISourceNodeConversionRule, jeśli jednak "wyciąga" zarówno wartość węzła źródłowego jak i docelowego, będzie implementowała dwa interfejsy ({ISourceNodeConversionRule} oraz ITargetNodeConversionRule{})
- reguła musi posiadać 0-argumentowy konstruktor oraz settery dla wszystkich jej niezbędnych parametrów
- jeżeli reguła produkuje wartość pola dziedzinowego na podstawie tylko jednej kolumny, może ona rozszerzać abstrakcyjną klasę AbstractXXXSingleColumnConversionRule, gdzie XXX jest typem danych zwracanym dla pola dziedzinowego, a sama klasa rozszerza abstrakcyjną (istniejącą już) klasę AbstractSingleColumnConversionRule.
- klasa AbstractXXXSingleColumnConversionRule powinna definiować metodę fetchDomainField(DataRow row) :: XXX, która z podanego (jako parametr metody) wiersza i ustawionego (jako wartość atrybutu klasy) indeksu kolumny "wyciąga" wartość typu XXX
- aktualnie istnieją dwie klasy rozszerzające AbstractSingleColumnConversionRule - są to: AbstractStringSingleColumnConversionRule oraz AbstractDateSingleColumnConversionRule
- Dodać nową regułę konwersji jako extension do punktu rozszerzeń pl.edu.agh.cast.importer.base.conversionrule
- wartość atrybutu point musi wskazywać na klasę nowej reguły
- Zarejestrować plugin importer-base jako buddy pluginu zawierającego nową regułę (patrz niżej)
Dynamiczny import klas reguł
W OSGi wszystkie wykorzystywane klasy muszą być explicite zaimportowane lub określone w zależnościach danego pluginu. Dlatego moduł, zawierający nowe reguły konwersji, musi zawsze zarejestrować plugin importer-base jako buddy (tak, aby ten potrafił odnaleźć nowe klasy reguł).
Zatem plugin importer-base ma w pliku MANIFEST.MF ustawioną politykę akceptowania "zaprzyjaźnionych" pluginów:
Eclipse-BuddyPolicy: registered
Oznacza to, że class loader modułu importer-base będzie szukał definicji klas we wszystkich zarejestrowanych pluginach (tzw. buddies).
Następnie moduł, który udostępnia nowe klasy reguł konwersji dla importera, w swoim w pliku MANIFEST.MF musi posiadać wpis:
Eclipse-RegisterBuddy: pl.edu.agh.cast.importer.base
Dzięki temu plugin z nowymi regułami oraz plugin importer-base będą "zaprzyjaźnione", co pozwoli pluginowi importer-base na dostęp do klas pluginu z regułami, pomimo istnienia zależności w drugą stronę.
Dodawanie nowego konwertera
Konwertery importu są specyficzne dla konkretnego modelu dziedzinowego, gdyż są świadome i zależne od rodzaju pól dziedzinowych.
Aby dodać do importera nowy konwerter należy:
- Utworzyć konwerter, spełniający następujące warunki:
- klasa konwertera musi implementować interfejs IImportConverter lub rozszerzać abstrakcyjną klasę AbstractImportConverter
- dla każdego pola dziedzinowego konwerter musi posiadać regułę konwersji implementującą interfejs reguły dla danego pola; np. model podstawowy posiada 3 pola dziedzinowe: węzeł źródłowy, węzeł docelowy i datę połączenia, zatem konwerter dla tego modelu musi posiadać 3 atrybuty: regułę konwersji dla węzła źródłowego implementującą interfejs ISourceNodeConversionRule, regułę konwersji dla węzła docelowego implementującą interfejs ITargetNodeConversionRule oraz regułę konwersji dla daty implementującą interfejs IDateConversionRule
- Dodać nowy konwerter jako extension do punktu rozszerzeń pl.edu.agh.cast.importer.base.converter
- wartość atrybutu point musi wskazywać na klasę nowego konwertera
- Uwaga
- Na dzień dzisiejszy, dane o konkretnych konwerterach NIE są pobierane z punktu rozszerzeń. W tym momencie, konkretne strony kreatora importu, służące do wyboru reguł konwersji, "są świadome" konwertera, który ma zostać zastosowany w odpowiadających im modelach dziedzinowych (stąd informacja z punktu rozszerzeń nie jest im potrzebna). Punkt rozszerzeń jednak pozostał - dla spójności, oraz do ewentualnego przyszłego zastosowania.
Dodawanie nowego modelu dziedzinowego
Najbardziej pracochłonną operacją rozszerzenia importera jest dodanie nowego modelu dziedzinowego w całości. Zakładając, że sam model dziedzinowy już istnieje, dodanie go do importera wymaga następujących kroków:
- Dodać nowy model dziedzinowy jako extension do punktu rozszerzeń pl.edu.agh.cast.model
- Utworzyć nowe typy danych (opcjonalnie)
- Dla każdego nowego typu danych utworzyć analizator (opcjonalnie jeśli pkt.2)
- Dodać nowe typy danych (z nowymi analizatorami) do importera (opcjonalnie jeśli pkt.2 i pkt.3), więcej...
- Dla każdego pola dziedzinowego utworzyć interfejs reguły konwersji
- Utworzyć konkretne implementacje reguł konwersji (opcjonalnie)
- Dodać nowe konkretne implementacje reguł konwersji do importera (opcjonalnie jeśli pkt.6), więcej...
- Utworzyć nowy konwerter (specyficzny dla nowego modelu dziedzinowego), zawierający regułę konwersji dla każdego pola dziedzinowego
- Dodać nowy konwerter do importera, więcej...