Projekt nadrzędny
Dokumentacja użytkownika
API dla programistów
Dokumentacja techniczna
- Wstęp
- Reprezentacja danych
- Przepływ danych
- Proces importu
- Hierarchia wyjątków
- Obsługa błędów
Ostatnio opublikowano: 25-06-2010
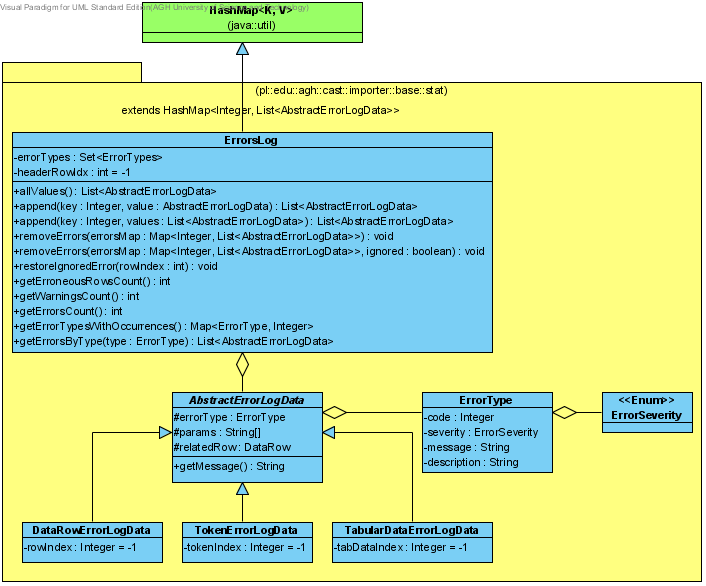
Błędy, występujące podczas procesu importu danych, opisywane są za pomocą następujących klas:
Wszystkie błędy w postaci AbstractErrorLogData zbierane są do logu błędów ErrorsLog. Log jest mapą, przechowującą mapowania pomiędzy indeksami błędnych wierszy a błędami, które w tych wierszach wystąpiły. Potrafi analizować błędne wiersze i same błędy, np. zliczając ilość wystąpień błędów różnego poziomu lub pobierając liczbę wystąpień błędów różnego typu. Log posiada również metody służące do cofania raz wykonanych operacji usunięcia błędów, oraz powtarzania operacji raz cofniętych.
Rysunek 1: Diagram zależności pomiędzy klasami służącymi do obsługi błędów procesu importu.