Projekt nadrzędny
Dokumentacja użytkownika
API dla programistów
Dokumentacja techniczna
- Wstęp
- Reprezentacja danych
- Przepływ danych
- Proces importu
- Hierarchia wyjątków
- Obsługa błędów
Ostatnio opublikowano: 25-06-2010
Import danych odbywa się 3-krokowo:
Zadaniem klasy Import Process jest obsługa wszystkich etapów importu danych. Na początku procesu importu tworzona jest nowa instancja tej klasy. Następnie ustawiane są kolejne parametry importu tj.:
Klasa ImportProcess udostępnia metody obsługujące kolejne etapy konwersji:
Dostęp do przetworzonych danych udostępniany jest przez metody:
Metody pomocnicze klasy służą do sprawdzania stanu procesu (canConvert(), canTokenize, canParse()) oraz do udostępniania podglądu (getTokenizePreview() oraz getConversionPreview()).
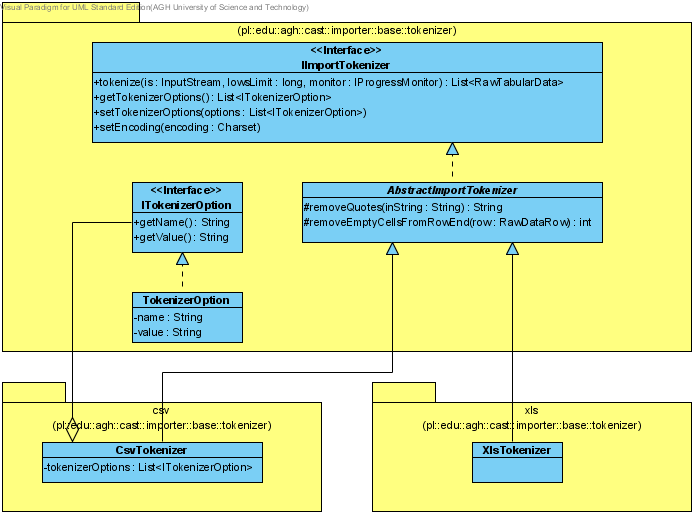
Tokenizator konwertuje strumień danych wejściowych (z pliku) do listy tabel rekordów List<RawTabularData>. Ponieważ tokenizator nie zna sensu danych (nie wie, co jest "w środku"), wiersze zwracanych tabel mogą być różnej długości (posiadać różną ilością komórek w rekordzie).
Tokenizator jest zależny od formatu pliku wejściowego (CSV, TXT, XLS), przy czym dla jednego typu plików może istnieć wiele tokenizatorów.
Każdy tokenizator rozszerza klasę abstrakcyjną AbstractImportTokenizer, która, z kolei, implemenutje interfejs IImportTokenizer:
public interface IImportTokenizer {
public List<RawTabularData> tokenize(InputStream dataIs, long rowsLimit, IProgressMonitor monitor)
throws IOException;
public List<ITokenizerOption> getTokenizerOptions();
public void setTokenizerOptions(List<ITokenizerOption> options);
public void setEncoding(Charset charset);
}
Najważniejszą metodą, którą każdy konkretny tokenizator musi zdefiniować jest metoda tokenize. Metoda ta czyta strumień wejściowy is i dzieli go na tokeny, zgodnie z wyspecyfikowanymi w options opcjami danego tokenizatora oraz z wyspecyfikowanym w charset kodowaniem znaków. Ogranicza się ona do rowsLimit liczby zaimportowanych rekordów. Dodatkowo, operacja tokenizacji monitorowana jest przy pomocy monitora postępu - monitor.
Każdy tokenizator może definiować własne opcje ITokenizerOptions:
public interface ITokenizerOption {
public String getName();
public String getValue();
}
Najważniejszymi opcjami tokenizatora są separatory komórek, rekordów i tabel, znaki komentarza oraz kwalifikatory tekstu.
Rysunek 1: Relacja klas powiązanych z tokenizacją w procesie importu danych.
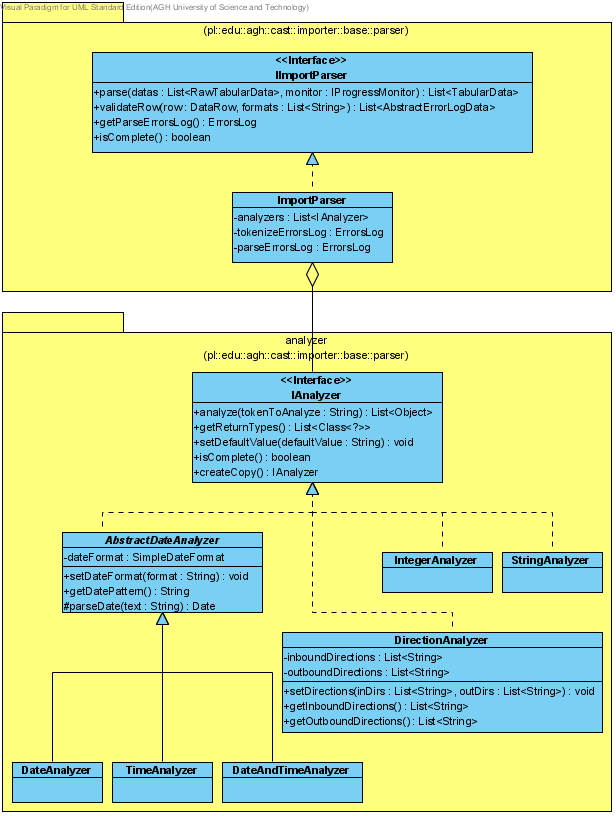
Parser przeprowadza analizę syntaktyczną danych w poszczególnych rekordach, w efekcie tworząc listę tabel obiektów - List<TabularData>. Istnieje dokładnie jeden parser dla wszystkich modeli dziedzinowych (ImportParser).
Parser posiada zbiór analizatorów IAnalyzer, na podstawie których przeprowadzana jest analiza poszczególnych tokenów (komórek) w kolejnych nieprzeanalizowanych wierszach RawDataRow, prowadząca do wytworzenia wierszy przeanalizowanych - DataRow. Zawartość każdej komórki wejściowej tabeli danych mapowana jest (za pomocą odpowiedniego analizatora) do odpowiedniego typu, np. String, Date, Integer.
Interfejs IImportParser oraz jego konkretna implementacja ImportParser deklarują (i definiują) następujące metody:
public interface IImportParser {
public List<TabularData> parse(List<RawTabularData> rawTabularDatas,
IProgressMonitor monitor);
public List<AbstractErrorLogData> validateRow(DataRow rowToValidate,
List<String> formats);
public ErrorsLog getParseErrorsLog();
public boolean isComplete();
}
Pojedynczy analizator obsługuje ściśle określony typ tokenów, co pozwala na przetworzenie konkretnego tokena, podanego w postaci Stringa do określonego typu obiektów. Każdy konkretny analizator implementuje interfejs IAnalyzer oraz definiuje następujące metody:
public interface IAnalyzer {
public List<Object> analize(String tokenToAnalyze) throws UnsupportedTokenException;
public List<Class<?>> getReturnTypes();
public void setDefaultValue(String defaultValue);
public boolean isComplete();
public IAnalyzer createCopy();
}
Metoda analyze zwraca listę odpowiednich, dla danego analizatora, typów obiektów. Przykładowo, analizator dat - DateAnalyzer zwraca listę obiektów typu Date, podczas gdy analizator liczb - IntegerAnalyzer zwraca listę obiektów typu Integer.
Tabela 1 przedstawia listę aktualnie zaimplementowanych analizatorów.
| Klasa | Dodatkowe atrybuty | Typy zwracanych obiektów | Opis |
|---|---|---|---|
| DateAnalyzer | format daty | DateDataType | Analizuje podany token i zwraca obiekt(y) typu DateDataType |
| DateAndTimeAnalyzer | format daty i czasu | DateAndTimeDataType | Analizuje podany token i zwraca obiekt(y) typu DateAndTimeDataType |
| DirectionAnalyzer | teksty dla kierunku przychodzącego, teksty dla kierunku wychodzącego | DirectionDataType | Analizuje podany token i zwraca obiekt(y) typu DirectionDataType |
| IntegerAnalyzer | brak | Integer | Analizuje podany token i zwraca obiekt(y) typu Integer |
| StringAnalyzer | brak | String | Analizuje podany token i zwraca obiekt(y) typu String |
| TimeAnalyzer | format czasu | TimeDataType | Analizuje podany token i zwraca obiekt(y) typu TimeDataType |
Wszystkie analizatory połączone są w swego rodzaju maszynę stanów. Parser wie, który analizator może (ew. które analizatory mogą) zakończyć analizę pojedynczego rekordu. W przypadku gdy dany rekord zakończy się w analizatorze nie-końcowym, zgłoszony zostanie odpowiedni błąd parsingu (np. wiersz za krótki/za długi).
Poza prostym potokowym przetwarzaniem tokenów (ciąg analizatorów), istnieją dwa dodatkowe rodzaje zachowań parsera:
Każda wynikowa tabela danych TabularData posiada dokładnie tyle kolumn, ile analizatorów w maszynie stanów parsera (dla MULTIPLE TYPE tworzone są osobne kolumny dla osobnych typów; dla SEPARATE FLOW tworzone są osobne kolumny dla każdej pozycji przebiegu).
W fazie analizy syntaktycznej (parsowania) następuje również wstępna weryfikacja syntaktyczna pól, np. braku pewnych danych (bez określenia czy dane te były obowiązkowe czy opcjonalne), poprawnego typu danych, poprawnego formatu danych (np. daty), itp. Błędy mogą dotyczyć zarówno pojedynczych komórek (np. token, który powinien być datą nie może być do niej przekonwertowany), jak i całych wierszy (np. wiersz jest za krótki/za długi). Błędy przechwytywane przez parser podzielone są na błędy fazy tokenizacji oraz błędy fazy parsingu. W parserze przechowywane są one postaci logów błędów - ErrorsLog. W tym momencie błędy tokenizacji nie są brane pod uwagę podczas procesu importu danych (stąd interfejs IImportParser wystawia jedynie metodę getParseErrorsLog).
Parser NIE jest zależny od modelu dziedzinowego. W chwili obecnej zaimplementowany został jeden - uniwersalny - parser: ImportParser, który przeprowadza operację parsowania na podstawie prostej listy analizatorów otrzymanej w konstruktorze. Ponieważ maszyna stanów analizatorów sprowadzona została do prostej listy, parser ten nie obsługuje jeszcze bardziej złożonych zachowań, tj. MULTIPLE TYPE, czy SEPARATE FLOW.
Rysunek 2: Relacja klas powiązanych z analizą syntaktyczną (parsingiem) w procesie importu danych.
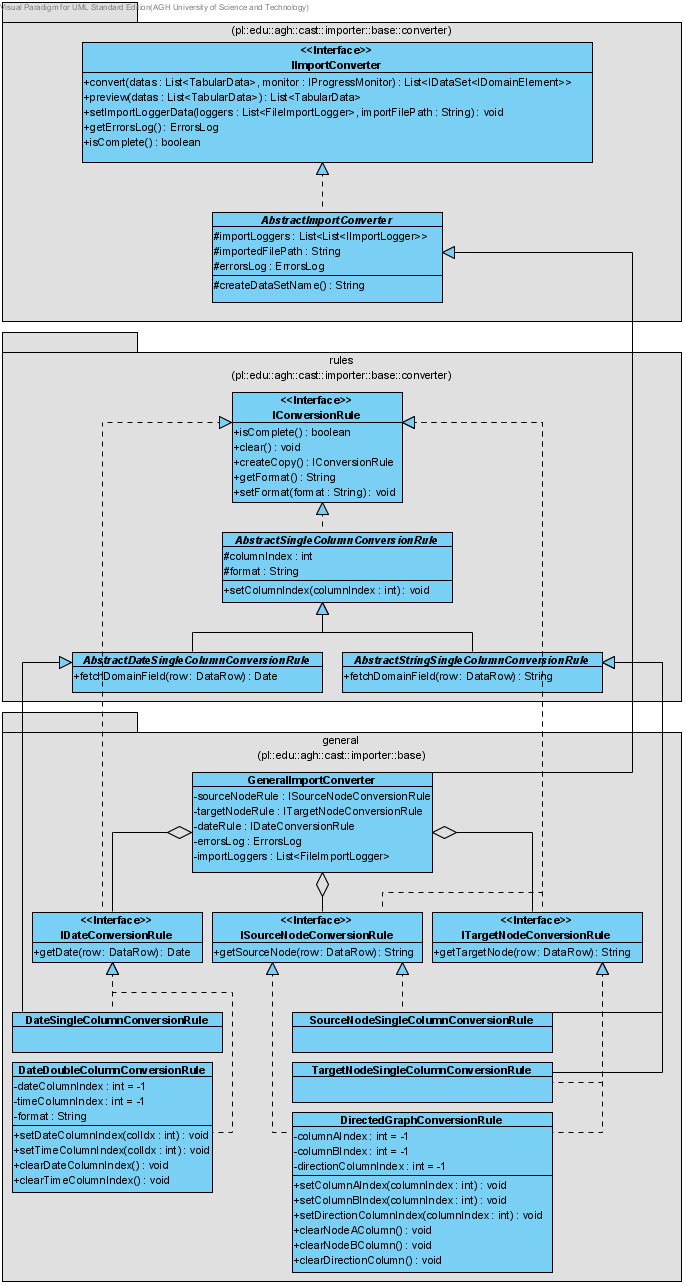
Na podstawie zapisanych w szablonie reguł konwersji (strategii), wykonywana jest konwersja danych z tabel obiektów (List<TabularData>) do zbiorów danych w określonym modelu dziedzinowym - List<IDataSet<IDomainElement>>.
Każdy konwerter jest specyficzny dla konkretnego modelu dziedzinowego - zależny od rodzaju pól, jakie w tym modelu mogą występować. Wiedza o możliwych polach dziedzinowych konieczna jest do wytworzenia odpowiedniego rodzaju wynikowego zbioru danych. Wszystkie konwertery implementują interfejs IImportConverter i definiują następujące metody:
public interface IImportConverter {
public List<IDataSet<IDomainElement>> convert(List<TabularData> tabularDatas,
IProgressMonitor monitor);
public List<TabularData> preview(List<TabularData> tabularDatas);
public void setImportLoggerData(List<FileImportLogger> importLoggers,
String importFilePath);
public ErrorsLog getErrorsLog();
public boolean isComplete();
}
Podobnie jak parser przeprowadza analizę syntaktyczną na podstawie listy określonych w nim analizatorów, tak konwerter przeprowadza analizę semantyczną na podstawie określonych w nim reguł konwersji IConversionRule.
Pojedyncza reguła konwersji implementuje interfejs IConversionRule oraz jego metody:
public interface IConversionRule {
public boolean isComplete();
public void clear();
public IConversionRule createCopy();
public void setFormat(String formats);
public String getFormat();
}
Dla każdego pola dziedzinowego definiowany jest osobny interfejs, rozszerzający interfejs IConversionRule, i definiujący metodę getXXX(DataRow) throws ConversionRuleException, IllegalArgumentException, gdzie XXX jest nazwą pola dziedzinowego. Pojedyncza reguła może wytwarzać więcej niż jedno pole dziedzinowe - w takim wypadku implementuje odpowiednio więcej interfejsów. Dzięki powyższej hierarchii interfejsów, istnieje prosty sposób na dodawanie kolejnych reguł konwersji, bez zmiany implementacji konkretnego konwertera dziedzinowego.
Tabela 2 przedstawia listę aktualnie zdefiniowanych interfejsów reguł konwersji dla modelu podstawowego.
| Interfejs | Metoda konwertująca | Opis |
|---|---|---|
| ISourceNodeConversionRule | getSourceNode(DataRow row) :: String | Pobiera z danego wiersza wartość węzła źródłowego (o typie String) |
| ITargetNodeConversionRule | getTargetNode(DataRow row) :: String | Pobiera z danego wiersza wartość węzła docelowego (o typie String) |
| IDateConversionRule | getDate(DataRow row) :: Date | Pobiera z danego wiersza wartość daty połączenia (o typie Date) |
Tabela 3 przedstawia listę aktualnie zaimplementowanych reguł konwersji dla modelu podstawowego, implementujących w/w interfejsy.
| Klasa | Implementowane interfejsy | Opis |
|---|---|---|
| SourceNodeSingleColumnConversionRule | ISourceNodeConversionRule | Konwertuje wartość pojedynczej komórki tekstowej do węzła źródłowego |
| TargetNodeSingleColumnConversionRule | ITargetNodeConversionRule | Konwertuje wartość pojedynczej komórki tekstowej do węzła docelowego |
| DateSingleColumnConversionRule | IDateConversionRule | Konwertuje wartość pojedynczej komórki o typie Date do daty połączenia |
| DateDoubleColumnConversionRule | IDateConversionRule | Konwertuje wartość jednej komórki z datą (DateDataType) oraz jednej komórki z czasem (TimeDataType) do daty połączenia |
| DirectedGraphConversionRule | ISourceNodeConversionRule, ITargetNodeConversionRule | Konwertuje wartość dwóch komórek tekstowych oraz jednej komórki o typie Direction do węzła źródłowego oraz docelowego |
W fazie konwersji wykonywana jest również weryfikacja semantyczna danych pod kątem ich integralności (np. czy istnieją pola obowiązkowe), jak również pod kątem możliwości przekonwertowania danych na podstawie wybranych przez użytkownika reguł konwersji. Wszystkie błędy konwersji przechowywane są w konwerterze w postaci logu błędów - ErrorsLog - i logowane do odpowiedniego pliku loggera.
Rysunek 3: Relacja klas powiązanych z analizą semantyczną (konwersją) w procesie importu danych, oraz ich rozszerzenie dla podstawowego modelu dziedzinowego.