Projekt nadrzędny
Dokumentacja użytkownika
API dla programistów
Dokumentacja techniczna
- Wstęp
- Reprezentacja danych
- Przepływ danych
- Proces importu
- Hierarchia wyjątków
- Obsługa błędów
Ostatnio opublikowano: 25-06-2010
Jako dane wejściowe rozumiemy plik zawierający interesujące nas dane, np. billing telefoniczny, wyciąg z konta bankowego.... Pliki te wczytywane są za pomocą tokenizerów, zależnych od formatu pliku wejściowego.
Obecnie obsługiwane formaty plików to:
| Format pliku | Klasa tokenizatora | Opcje tokanizatora |
|---|---|---|
| oddzielany separatorem .csv lub tekstowy .txt | CsvTokenizer | Separator rekordów, Znak komentarza, Kwalifikator |
| Microsoft Excel .xls | XlsTokenizer | brak |
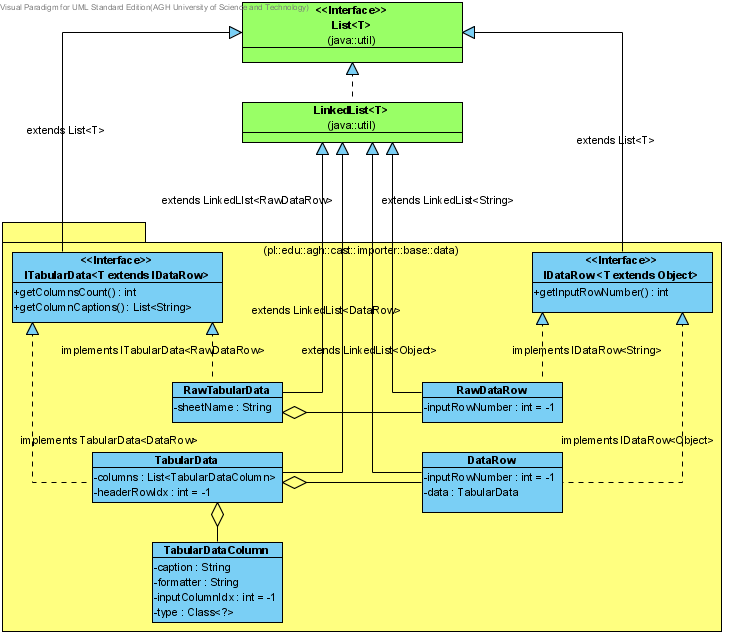
Po procesie tokenizacji strumienia danych z pliku, dane przechowywane są w formacie listy nieprzeanalizowanych tabel danych, reprezentowanych przez klasę RawTabularData.
Klasa RawTabularData jest listą rekordów RawDataRow (odpowiadających, w większości wypadków, pojedynczym wierszom danych – choć nie musi tak być), z których każdy jest listą nieprzeanalizowanych komórek stringów: List<String>. Wiersze nie muszą posiadać tej samej ilości kolumn. Każda komórka rekordu nie musi się mapować 1:1 z polem modelu dziedzinowego (np. osobne komórki mogą zawierać ulicę, miasto, kod pocztowy, a odpowiadają jednemu polu ‘adres’ w modelu dziedzinowym). Komórki w jednej ‘kolumnie’ zawierają dane o tym samym znaczeniu (jeśli rekord jest poprawny – jedna kolumna odpowiada dacie, druga adresowi itp.), jednak sam Tokenizer nie jest tego świadom. Jeśli w danych wejściowych zabraknie któregoś z pól rekordu (komórki), do komórki wstawiana jest wartość null.
W rezultacje procesu parsingu nieprzeanalizowanych tabel danych, powstaje lista przeanalizowanych tabel danych, reprezentowanych przez klas TabularData.
Klasa TabularData jest listą rekordów DataRow, z których każy jest listą przeanalizowanych komórek obiektów: List<Object>. Każdy wiersz tabeli obiektów DataRow odpowiada jednemu wierszowi danych wyjściowych. Komórki w jednej ‘kolumnie’ tabeli zawierają dane o tym samym znaczeniu.
Tabela obiektów zawiera również opisy poszczególnych, występujących w niej, kolumn w postaci listy TabularDataColumn. Każda kolumna TabularDataColumn posiada informacje niezbędne do prawidłowego wyświetlenia oraz obsługi danej kolumny, tj. nagłówek kolumny, sposób jej formatowania, typ danych w niej przechowywanych oraz mapowanie do numeru kolumny z pliku wejściowego.
Rysunek 1: Diagram zależności pomiędzy klasami reprezentacji danych importera.
Podczas procesu konwersji, wiersze (DataRow) przekształcane są w odpowiednie encje oraz relacje. Zbiór takich encji i relacji jest reprezentowany jako zbiór danych w określonym modelu dziedzinowym IDataSet<IDomainElement>.